
Manufacturers of artificial intelligence are developing their AI image generators faster than almost any software category before. Above all, Midjourney and Dall-E 2 show how difficult it is now to distinguish between a computer-generated portrait and an actually photographed one. Fakes can only be distinguished from facts in the details, such as unclean window frames or unnatural hand positions. Soon the line will completely blur. For the photo and advertising industry, this does not necessarily mean that jobs will disappear, but they will change, probably just as radically as in the nineties, when trained typesetters were forced in front of the screen. And the audience has to look even more closely to spot a fake image.



AI image generators are springing up like mushrooms, for example the “text to image” generator in the web app Canva or “Generate” from the photo agency Shutterstock. At the end of March, the beta of Adobe Firefly, an AI image generator that is closely linked to Adobe Stock and trained on its material, was released.
But the “classics” are also making a name for themselves: On March 17, Midjourney released version 5 of its image generator of the same name, which the manufacturer says has been trained with 5 billion parameters. With the update, the service reacts more precisely to text specifications (prompts), but also requires more detailed input. The stylistic range is growing: so far, Midjourney has mainly understood digital paintings, but now the service also creates photorealistic images. Above all, he can now convincingly reproduce the human anatomy.
Does the Pope wear Balenciaga?
Users immediately made headlines with it. The mid-journey portrait of the pope in the pristine white Balenciaga down coat rappers like to wear prompted the manufacturer to react. So far, you could generate 25 images for free with Midjourney. The trial version is no longer available. Too many people would have created several accounts to save money. According to Midjourney, it is also working on guidelines for responsible use of AI. Midjourney already has a list of banned words, for example to suppress pornographic content.

The Pope in a snow-white down coat: The AI portrait created with Midjourney made headlines. It looks amazingly realistic. Only the hands and the glasses reveal that this is an AI-generated image.
(Image: Midjourney)
Stable Diffusion 2.1 already went online in December 2022. In early April, the developer released the experimental model SDXL Beta. In addition to versions 1.5, 1.6, 2.0 and 2.1, it is available in the developer’s own service DreamStudio. It is said to have been trained on more than twice as many parameters – a total of 2.1 billion. Stable Diffusion 2 supports extreme aspect ratios like panoramas and negative prompts. They exclude what the picture should not show under any circumstances. The initially disconcerting entries such as “disfigured” and “too many fingers” help to avoid images with faulty anatomy, for example hands with six fingers. Positive and negative prompts can also be weighted with information such as 1.0 or -0.3.
OpenAI has released an experimental update for Dall-E 2 that should flow into the image generator. On openai.com but the old version still works. Since March 21, Microsoft Bing Chat has been directly accessing Dall-E 2 to generate images. This only works in creative mode and only with English text prompts. Bing Chat works with the latest version of Dall-E 2. The service still doesn’t show any prominent faces; it is said to have been trained on 3.5 billion parameters.

Four image examples each for AI-generated portraits from top to bottom: Midjourney 5, Dall-E 2 (via Bing Chat), Stable Diffusion XL (beta), Adobe Firefly (beta). The images of Midjourney and Dall-E can hardly be distinguished from real portraits. Stable Diffusion does passable. Adobe Firefly images can safely be considered completely unusable.
theory and practice
The images in this article show what the latest versions of the AI image generators do in portraits. They all come from the same text prompt. By default, most services eject four images at each prompt. The first line shows images of Midjourney 5, followed by four suggestions each from Dall-E 2 (via Bing Chat), Stable Diffusion XL (via DreamStudio) and finally Adobe Firefly.
They are designed to represent a photographic portrait in a mood-lit restaurant in the style of a classic 1970’s medium format camera with the color scheme of Fujifilm Polaroid instant film. The monumental entry read: “hyper-real nostalgic polaroid portrait in dimly lit stylish restaurant, capturing genuine emotions and character of subject, shot with Mamiya RB67 camera on Fujifilm FP-100C instant film, f/2.8 aperture, 1/30 shutter speed, sharp focus on individual’s expressive features and atmospheric surroundings, subtle film grain adding nostalgic authentic quality”.
Midjourney 5 in particular can handle such prompts well. But the latest versions of Dall-E 2 and Stable Diffusion also produce better results with longer presets. Only with Adobe Firefly did we have to shorten a few words. The results of the first three services are dramatically better than those of the last test.
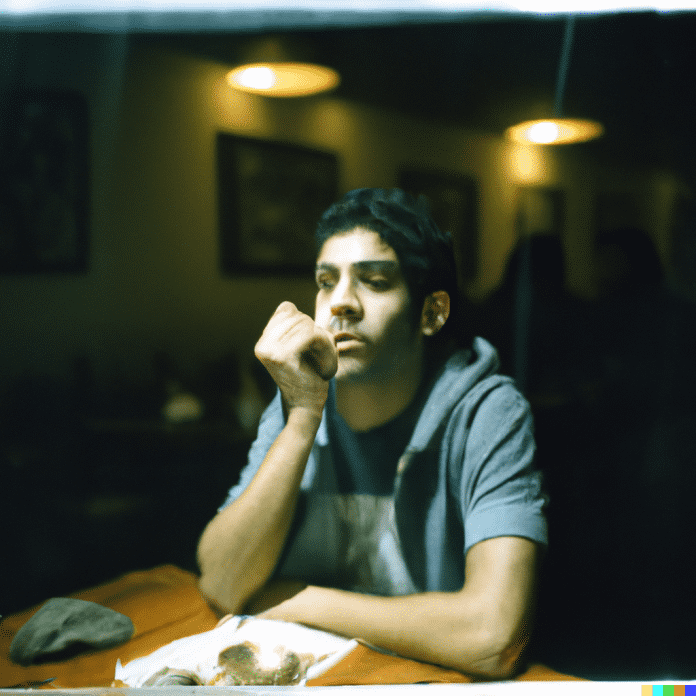
The version of Dall-E 2 on open.ai produces worse results (like here) than the one available via Bing Chat.
Impressive portraits
Midjourney 5 produces completely convincing portraits at first glance. Only details in the background, such as irregularities in window and picture frames or inconsistencies in sharpness in the extreme foreground, reveal that the images in the first row are the products of artificial intelligence. Midjourney reproduces the anatomy of the face, body and hands absolutely convincingly, only with their composition into a whole there is a problem: In the third picture from the left, for example, the shoulders and the hand fit the head. However, the position of the hand does not match the shoulder. But it takes a lot of time, a trained eye and a good deal of skepticism to discover such errors.
Dall-E 2 shows flawless portraits in the second line. The images generated by Bing Chat were head and shoulders above the results from openai.com. Unlike the mid-journey portraits, it’s hard to find fault with Dall-E 2. Any inconsistencies are concealed by the strong blurring of the background. The subjects’ skin is less textured than in Midjourney 5. Suit jackets, shirts and T-shirts, and facial features are absolutely convincing. Curiously, Midjourney decided exclusively for women, but Dall-E 2 only for men. The text prompt left open what kind of people the portraits should show.
Stable Diffusion also reveals significant advances in generating faces. The service provided by the developer dreamstudio.ai produces convincing results with the SDXL-Beta (see row three); however, there is something artificial about some of them. Hands and wrists still hold the generated characters in an unnatural way. Stable Diffusion 2.1 still completely ignores the setting of a darkly lit restaurant, but SDXL now implements it correctly.
The images generated by Adobe Firefly are a complete failure. The features of the people depicted in the fourth row appear distorted and unnatural. The youthful male facial features contrast with the clothing styles of older women. The service also misunderstands the information on the photographic style – they materialize as photos floating in space without context. The second image even shows the camera on the person’s shoulder, the style of which the image is intended to simulate.
(Bild: c’t 10/2023 )
The language models learn to surf! AI search engines scour the web for you and link your sources. c’t tests seven search services with AI support and shows new security risks that arise as a result. The upcoming end of support for Windows 10 threatens to turn working computers into electronic waste, because many computers do not meet the requirements for Windows 11. We ask what politics and business actually have to say about this. We also tested mini PCs, explain how to bring back deleted files under Linux and remember the c’t “Hommingberger Gepardenforelle” campaign. You can read that and more in c’t 10/2023!
(acres)
