
With Visual ChatGPT, Microsoft has released a multimodal conversation model that builds on ChatGPT and combines OpenAI’s AI system with various Visual Foundation Models (VFM) such as Stable Diffusion. With such basic visual models, computers can analyze complex images and generate them themselves. The team of scientists around senior researcher Dr. Chenfei Wu of Microsoft Asia in Beijing about not wanting to train multimodal ChatGPT from scratch. Instead, the central Prompt Manager for Visual ChatGPT selects the appropriate models for the job based on the user instructions. Visual ChatGPT is likely to be one of the multimodal models announced by Microsoft Germany at the beginning of March 2023.
Otherwise, Visual ChatGPT can describe the content of images and answer questions about images. For example, Visual ChatGPT explains what could happen if you stick a needle in a balloon.
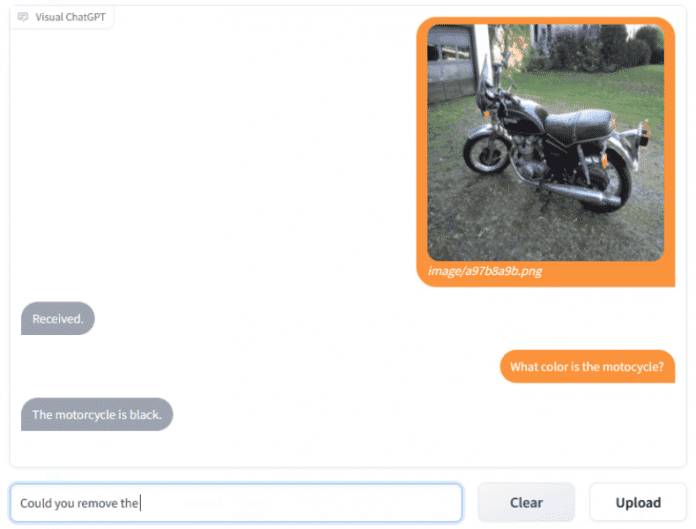
Chatverlauf in Visual ChatGPT
(Image: Microsoft)
For this purpose, Visual ChatGPT uses, among other things, the BLIP model (Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation, Paper at arXiv.org). The ControlNet AI model, for example, helps with additional instructions to control the AI image generator Stable Diffusion by incorporating an interactive feedback loop into the image creation process. Conversational AI like ChatGPT can customize this prompt so that Visual ChatGPT provides a result or revises the output in further iterations based on user feedback.

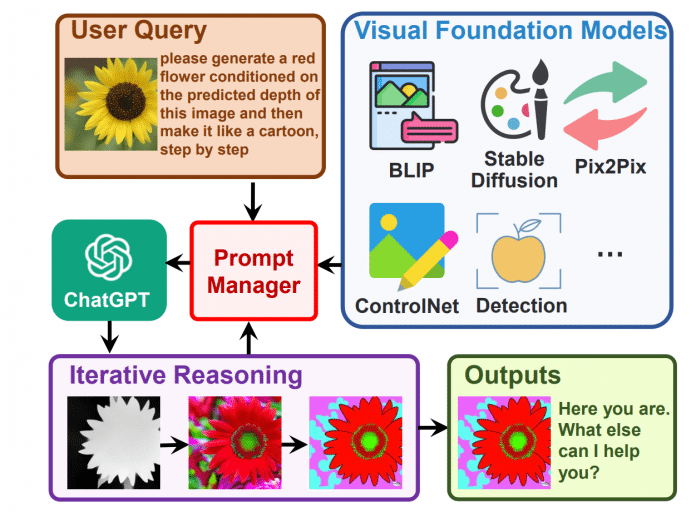
Architecture of VisualGPT
(Bild: Chenfei Wu et al.)
Image editing with Visual ChatGPT
In addition to passing prompts to Stable Diffusion, Visual ChatGPT can also edit or explain images in chat on instructions. Anyone who wants to add a different background or color to an image for an item can do so through chat. It is also possible to post simple hand-drawn sketches to the chat and have them enhanced or edited.
According to the Microsoft Asia team, Visual ChatGPT is highly dependent on ChatGPT and needs access to OpenAI’s AI chat system to assign tasks. It also depends on access to other Visual Foundation Models to perform the tasks. Therefore, the performance of Visual ChatGPT also depends on these models.
Visual ChatGPT supports Meta AI’s SegmentAnything

Sample segmented image by SegmentAnything Model (SAM), Facebook AI Research
(Bild: Facebook AI Research (FAIR))
Microsoft’s VFM now also supports GroundingDINO and SegmentAnything Model (SAM). Facebook AI Research (FAIR or Meta AI) published the image segmenter SAM in early April 2023. This allows objects to be cut out with pixel precision, valid masks can be created for every text input and users can add or exclude areas. Meta AI laid that with it first basic model for image segmentation before. AI professionals who work professionally on multimodality call SegmentAnything “a GPT-3 moment for computer vision” because Meta’s segmenter has a strong understanding of context.
Users can send a request to Visual ChatGPT via a chat in different languages such as English or Chinese and also provide pictures. The code written entirely in Python or mainly in Jupyter Notebook Visual ChatGPT is freely available on GitHub under the MIT license. According to the repository, if you want to try out Visual ChatGPT, you also need OpenAI API access. This can result in additional costs.
Other providers and also open source associations such as LAION are currently working on open source alternatives to the products from OpenAI and Microsoft in order to give users and developers options and to further democratize AI development. OpenAssistant has just been released as a ChatGPT alternative.
(mack)