
Researchers from Google and Stanford University have used ChatGPT to control the communication and behavior of simple autonomous software agents in a simulated environment. The 25 software agents who “live” and “work” in the virtual community called “Smallville” point to Information provided by the researchers not only “realistic human behaviors” but also “emergent social interactions”. For example, the plan to celebrate a Valentine’s Day party that was given to one of the agents resulted in the simulated person sending out invitations to other agents and decorating the room in which the celebration was to take place beforehand – and doing so because of the time was scarce, even organized help.
“Generative agents wake up, make breakfast, and go to work; artists paint while writers write; they form opinions, perceive each other, and start conversations; they remember and reflect on days gone by as they face the next day planning”, write the researchers in their paper, for which there is also a demo version.
However, the software agents do not actually carry out all these actions. Rather, they are output as text, which in turn serves as input to other agents, just like the description of each location in Smalville. In a way, the language model speaks to itself in different roles and simultaneously plays through the actions of 25 agents as in a text-based role-playing game.
New behavior of software agents
The advantage of this is that the spectrum of agent behavior is surprisingly diverse. Although the simulation of behavior in a model environment is not new – US scientists use multi-agent gene systems, for example, to test political measures against the opioid crisis – but the software agents in such a simulation usually act on the Based on simple if-then rules. Their range of behavior is therefore very limited. In the past, examples of agents with “cognitive architecture” that are able to learn and develop new behaviors have also been shown. However, their abilities were reduced to how to shoot enemies – communicating and working together is far too complex for them.
Language models can do much more – especially communicate. However, one of the problems that Joon Sung Park and his colleagues had to solve is the limited “context length” of the language model. The input prompt, which must contain information about the virtual location, the agent’s history and possible destinations, has a maximum length of 2,048 tokens – which roughly corresponds to 6,000 words. In order to have the agents act consistently, the researchers linked the language model to a database containing the “memory stream” of each agent.
On the one hand, the file consists of the agent’s “observations” – where am I, what is the condition of the objects at this location? What am I doing? – which are provided with a time stamp. Also included in the stream of memories are more abstract summaries of events and interactions, as well as plans and intentions. The authors also have ChatGPT generate both abstract summaries and plans. Before each action, a query module then searches for the most recent and most relevant entries from the memory stream and uses them to generate the context for the next input prompt.
Interactions between agents
It would be relatively obvious to attribute a kind of intelligence to the software agents. However, the authors of the paper do not do this, although similar systems that link large language models with external software such as planning modules etc. and “do autonomously, just attract a lot of attention. Whether large language models can do more than just supplement texts – in particular, draw logical conclusions, create plans or speculate on the goals and intentions of other agents or humans – is currently heavily disputed. In principle, they are “only” text supplements. In fact, large language models such as ChatGPT can always solve tasks of this type in the form of fictitious scenarios. From a purely pragmatic point of view, the system actually works.
In the publication, the researchers list three “emergent” behaviors that arose solely from interactions between agents: “information-diffusion” agents passed information when appropriate — coordination of actions among multiple agents, and that Establishing new relationships with each other. Charmingly, the researchers were able to check this directly by repeatedly “interviewing” the individual agents during the ongoing simulation.
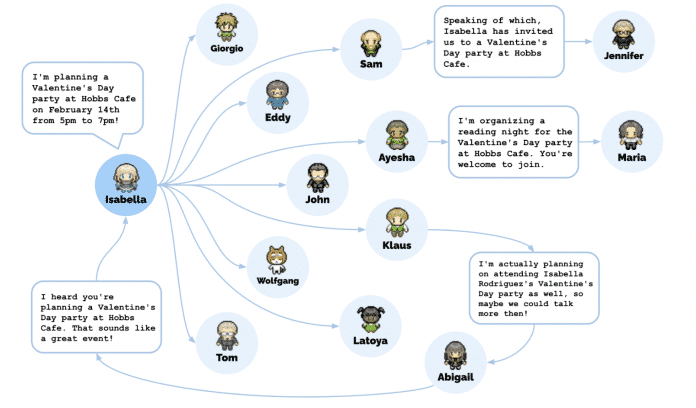
The “information diffusion” agents passed on information when appropriate. By the end of the simulation, a total of twelve agents had heard about Isabella’s party at Hobbs Cafe.
(Image: Joon Sung Park et al.)
However, the system is too slow and too computationally intensive to use the agents in computer games. The researchers therefore suggest using the software for designing online communities, for example, because it can be used to test the effects of certain rules and behaviors. Nevertheless, this system also has to contend with a fundamental problem that plagues all applications of large language models: the authors do not know whether the system is stable. So far they have only run the simulation for two virtual days. There is definitely a risk that the language model will hallucinate or get out of hand linguistically – and individual agents will then no longer be able to interact with the others.


(jl)